TFQA: Tools for Quantitative Archaeology
kintigh@tfqa.com +1 (505)
395-7979
TFQA Home
TFQA Documentation
TFQA Orders
Kintigh(ASU
Directory)
|
TFQA: Tools for Quantitative Archaeology |
TFQA Home |
Overview of ProgramsTools for Quantitative Archaeology is a commercial package of Windows programs developed to satisfy the unusual analytical needs of archaeologists. The focus of the package is on methods developed for archaeology and not included in general-purpose statistical packages. While this package can perform many important analyses, it is not a complete substitute for a general purpose statistical package. This page provides an overview of the available programs Complete documentation is available though the website here. While this web site describes each of the programs in the package, at the moment, the graphics display poorly over the web. However they are, in fact, publishable quality vector graphics that can be printed directly on a printer or plotter that supports HPGL or may be manipulated and printed by most programs that process graphics, including word processors. A few programs highlighted in purple, are available, without obligation, as freeware and can be downloaded from this web site. In most cases these Windows executables of these programs are accompanied by documentation, sample input files, and Delphi (Pascal) source code. Full references for works cited below are provided in the TFQA Bibliography.
CONTIG - Monte Carlo evaluation of the statistical significance of the observed degree of contiguity of grid units assigned to the same cluster. This is useful when the cluster assignments have been derived in a way that is independent of their spatial location, for example, in an unconstrained clustering analysis. You may download contig.zip, which includes the program and a sample data file. See Papalas, Clark, and Kintigh (2003). Documentation FISHER - Calculates Fisher's Exact test, useful for mean- or median-split grid count analyses such as those described by Spurling and Hayden (1984). Documentation GRID - Aggregates point-provenience data into counts by type for each grid unit. The grid can have any origin and grid units can be of an arbitrary rectangular size. A weighting option permits use of GRID on data sets in which multiple objects at the same location are recorded on a single input record. The program can be used in performing a grid-based variant of Whallon's unconstrained clustering with a point- provenienced data set. Documentation HOA - Computes Hodder and Okell's A and dispersion ratios (Hodder and Okell 1978). An extension permits Monte Carlo analysis of significance. Documentation KMEANS - Performs
k-means cluster analysis with extensive output designed to
facilitate interpretation. The program can be used to cluster
analyze any data set, but has special features developed for use
in archaeological spatial analysis. In particular, Kintigh and
Ammerman's (1982) k-means pure locational
clustering method can be performed. The program also
executes the clustering for Whallon's (1984) unconstrained
clustering method on data smoothed using the GRID or LDEN
programs. Results can be plotted with the KMPLT utility.
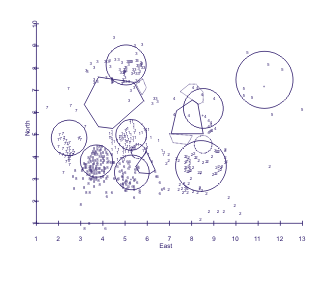
Also available in a version accepting CSV input. KMPLT - Plots the SSE and (2 dimensional) cluster configuration results of KMEANS on screen and creates hard-copy publishable quality plots (Figure 1). Although KMEANS will run much larger problems, KMPLT will only handle datasets with up to 2000 observations, 50 variables, and 30 clusters. Documentation KOETJE - Performs the Monte Carlo analysis of homogeneity of cluster configurations as suggested by Koetje (1987). Uses the output file from KMEANS or reads separate data sets consisting of counts of artifact class by cluster. An extension permits evaluation of individual cluster probabilities. DocumentationLDEN - Performs Johnson's (1984) Local
Density Analysis on point-provenienced or grid data. The program
also outputs counts or percentages of points of different types
that occur within a circular neighborhood around each data point.
These can be used with KMEANS to perform a variant of
unconstrained clustering (Whallon 1984). In a single run, it
computes inter-type local density coefficients for any number of
radii that can be plotted with LDPLT. 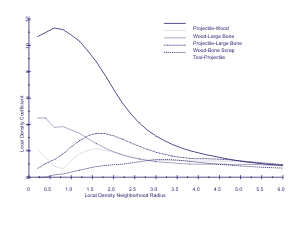
LDPLT - Plots selected local density coefficients computed by LDEN against radius, so behavior of coefficients for different pairs of classes can be easily observed over a range of radii (Figure 2). Documentation NEIG - An efficient, general-purpose nearest-neighbor (Whallon 1984) and gravity model program useful for intrasite spatial analysis or regional analysis. It allows categorization of items by class (e.g. site type or tool type) and permits the calculation of within or between class neighbors. Output includes nearest-neighbor statistics, summary data about the classification of nearest neighbors for points of each class and lists of the first n nearest-neighbors for each point. Monte Carlo analyses of significance can be performed. Documentation RANDPT - Generates random sets of coordinates, including for clumped distributions with different parameters. Also random walks any number of points in an existing distribution with arbitrary number of steps and step length. Available as freeware in randpt.zip. Documentation BOONE -
Calculates, for a set of proveniences with counts by artifact
class, Boone's (1987) assemblage heterogeneity measure and related
values. 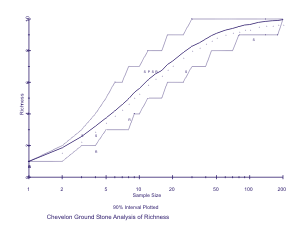
DIVERS - Calculates richness and evenness (H/Hmax) dimensions of diversity for a given data set and uses Monte-Carlo methods to derive expected diversity for a model distribution over a range of sample sizes (Kintigh 1984, 1989). It is capable of handling large problems efficiently. Results can be plotted with the utility DIVPLT. Documentation DIVMEAS - Calculates several diversity measures including Richness, Simpson's, Shannon's, Brillouin's, and the Renyi and Delta families of generalized diversity measures for any given distribution of counts. Documentation DIVPLT - Plots the results of DIVERS on screen and creates publishable quality plots (Figure 3). Documentation EVALC -
Performs a Monte Carlo evaluation of the significance of an
observed value of Simpson's C measure of diversity relative to a
given assumption about the population. RAREFY - Performs rarefaction analysis for sets of sample counts in a CSV file as described by Baxter (2001). Provides expected richness, standard deviation of the expected, Z score, and probability for each larger sample to every smaller sample size. Also outputs expected richness for each sample up to its sample size for graphing. Documentation BAYES - This program implements Bayesian methods for proportions as described by Iversen (1984). Intervals are calculated and graphed for Bayesian estimates of proportions based on both flat and informative priors. Documentation BINOMIAL - Computes binomial probabilities and population proportion intervals for a sample. Documentation BRSAMPLE - Provides a Monte Carlo estimate of the sampling error of differences of the Brainerd Robinson coefficient calculated between a sample and a known population or between two samples drawn from the same population as described and applied in Deboer et al. (1996).(Now replaced by resampleBRED. Documentation CLCA - Performs a Complete Linkage Cluster Analysis on up to 180 cases. It takes as input an upper triangular distance matrix, as is created by the DIST program. As output, it lists the sequence of item/cluster joins and fusion values but does not create a dendrogram. Documentation DIST
- Computes a triangular matrix of distance or similarity
measures: Euclidean Distance, Pearson's r,
Brainerd-Robinson Coefficient, Jaccard's Coefficient, Simple
Matching Coefficient, and Gower Coefficient. It handles up to
180 cases with 16,000 total input values (88 variables for 180
cases). (See Kintigh 2006 for some interesting applications.) Documentation 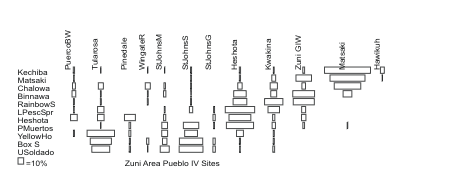
FORD - Plots a publishable quality battleship curve (Ford) diagram on the screen and optionally to a hard copy device. It reads a file of percents of types (columns) by provenience (rows) and optional row and column labels. The program permits interactive elimination or reordering of the rows and columns and replotting of the data. Documentation POISSON - Computes Poisson and negative binomial probabilities, given expected counts. Documentation resampleBRED - Provide Monte Carlo estimates of the sampling error of differences of the Brainerd-Robinson and Euclidean Distance coefficientscalculated between a sample and a known population or between two samples drawn from the same population, as described and applied in Deboer et al. (1996). (Replaces BRSAMPLE.) Documentation TWOWAY - provides tests of independence and measures of association and prints tables that have been standardized with a number of techniques. Standard Chi² and G tests of independence are provided. Using Monte Carlo methods, Chi² and G tests can be performed on tables with very small expected counts. A Chi² goodness of fit test (with externally determined expected values) can also be calculated. Measures of association include Yule's Q, Phi, Cramer's V and proportional reduction of error measures Tau and Lambda. Table standardization methods include median polish (Lewis 1986) and Mosteller (multiplicative) standardization as well as Haberman's z-score standardization for independent variables used by Grayson (1984) and Allison's binomial probability-based z-score standardization. It will also print row, column, and cell percents, Chi² cell contributions, and Chi² expected values. Also available in a version accepting CSV input. Documentation ARRANGE - creates a probabilistic estimate of the range of site dates based on the proportions of dated ceramic types in the assemblage. Output includes a density plot against time. The program also calculates mean ceramic dates. This method is described in Steponaitis and Kintigh (1993). The program is available as freeware at arrange.zip. Documentation C14 - provides a graphical way to analyze sets of radiocarbon dates. Each radiocarbon date is treated not as a single point in time but as a normally distributed probability with a mean and standard deviation given by the lab. In evaluating several dates, for each interval the probability distributions associated with the dates are summed. For each temporal interval, an expected number of dates is calculated and plotted in a histogram. Documentation CALCULATE_K - Calculates K for for use in Cowgill's formula that estimates the span of true interval producing an observed set of measured dates with Gaussian errors. It calculates the value of K for any standard deviation of a Normal Distribution. See Cowgill and Kintigh (2020). The program is freely available for download at https://github.com/kintigh/PhaseLen.Documentation DSPLIT - Compares and combines radiocarbon samples using the procedure published in Archaeometry by Wilson and Ward (1981). Documentation is limited to a description of the program prompts. Documentation MATCHINTERVAL - Performs a MonteCarlo evaluation of the correspondence between temporal intervals with extreme climate events and the occurrence dates of major cultural changes as described and applied by Kintigh & Ingram (2018). The program is freely available for download at https://github.com/kintigh/MatchInterval. Documentation PHASELEN
- Provides a Monte Carlo analysis to estimate the span of
true span producing an observed set of measured dates with
Gaussian errors such as radiocarbon and obsidian hydration
dates. The program has an option for
calibration. In test mode, the program can be used to
help decide how many dates are likely to be needed to obtain
a good estimate. The program comes with current
radiocarbon calibration files. Documentation ROOMACCUM - estimates within-period rates of population growth (or decline) given structure counts dated to a sequence of chronological periods as described and applied by Kintigh and Peeples (2020). It assumes a knowledge of the number of structures that date to each specific period, the period lengths, and an estimated structure use life. The population growth rate estimates are derived by simulating the construction (due to replacement and population growth) and abandonment (due to the completion of the use life or population decline) of individual structures such that the observed number of rooms dating to a period matches the simulated number of rooms. The program is freely available for download on GITHUB at https://github.com/kintigh/RoomAccum. Documentation PLACESTP calculates the optimal placement of test units in a rectangular or linear survey area. For a user-specified number of survey transects (or user-specified lengthwise and width-wise spacing of test units), in any one of three basic configurations, the program will print out the coordinates of the optimal test unit placement, along with some statistics about the largest circular site that can go unsampled in the survey area. This program implements the formulae provided by Krakker, Shott, and Welch (1983) and revised in Kintigh (1988). Documentation STP - Probabilistic evaluation of subsurface testing designs as described in Kintigh 1988. STP uses Monte-Carlo methods to evaluate the effectiveness of a test unit layout within a survey area to locate sites with a given size and artifact density. An old DOS version STPDOS that produces graphics is also provided. Documentation ADFUTIL - Generates random data sets and manipulates files in the data format used by the analysis programs. It allows the creation of random data set of any size. Variables may be uniform or normally distributed variables with user specified ranges or means standard deviations. ADFUTIL allows the deletion of columns (variables), selective deletion of rows (observations) based on values in a column, replacement of values in a column, randomization of columns for Monte Carlo analysis, the addition of new columns from another data set, and selection of a random sample of cases.Documentation CNTCNV - Program to speed data input and increase entry accuracy for count data, where the number of categories is large relative to the number of items counted for an observation (e.g. surface collection counts of 40 ceramic type divided into 8 vessel forms). It permits a highly abbreviated input format but it writes out a standard matrix (of the sort read by most analysis programs) with one count per category of each observation. The program provides labeled printouts of the data and can perform elaborate aggregation of count categories and simple aggregation of observations. Documentation CntEdit - CntEdit is a companion program to CNTCNV and can be used to do global or selective substititions of row or column field values in a data file formatted for CNTCNV. Documentation CntRefmt - CntRefmt is a companion program to CNTCNV that reformats row-column-count segments of records formatted for CntCnv, e.g, to make differently formatted files consistent or to change the spacing to make reading easier. Documentation CONVSYS - Converts a SYSTAT internal format data file into a raw data file, a variable label file, and a case label file that can be used these and other programs that read free-format ASCII data. Works with versions 2.0 and above of SYSTAT, on files of any size. Documentation HPPLOT provides a flexible user interface to a Hewlett Packard compatible plotters. Its can create a customized analysis graphics from a raw data file edited to include the plot commands. Documentation MVC - Permits arbitrarily complex copying of sets of columns in an input record into sets of columns in an output record. It can extract data from fixed-format data records for use with analytical programs that require free format input. Files of any size can be processed. Documentation SCAT - Produces screen and publishable quality scatter plots of variables. All points may be plotted with the same symbol, or different symbols can be plotted based on the value of a variable. Documentation SAMPMEAN - Interactively illustrates the process of sampling, and and how radically the means of different sized random samples can differ from the population mean. Running through a large number of trials illustrates the central limit theorem. A teaching tool. Documentation SORTLINE - A general purpose sort utility, SORTLINE sorts fixed-format data files of up to 32,767 lines into an order defined by any number of user-specified sort fields. Documentation SPLIT - divides a large file into sections that can be recombined with the DOS COPY command. Thus, large hard disk file can be split and copied onto several floppies. Documentation UNTAB - Replaces tabs and control characters in a file with blanks so they can be used with analysis programs that require pure ASCII files (e.g. SYSTAT). Documentation |
| Home | Top | Program Overview | Ordering | Documentation | Bibliography |
| Page Updated: 12 February 2026 |